发布日期:2026-05-17 16:48点击次数:


本考虑由中山大学、好意思协调合完成,第一作家王豪为中山大学博士考虑生,主要考虑标的为图像和视频分割、通达场景视觉感知、多模态大模子等。论文共同通信作家为梁小丹陶冶和蓝湘源副考虑员。
如今,多模态大模子照旧偶然看图、看视频,并回回应杂问题。但如若进一步条款模子「把画面中的某个见识精确分割出来」,问题就变得莫得那么简便。举例,用户提倡这么一个需求:
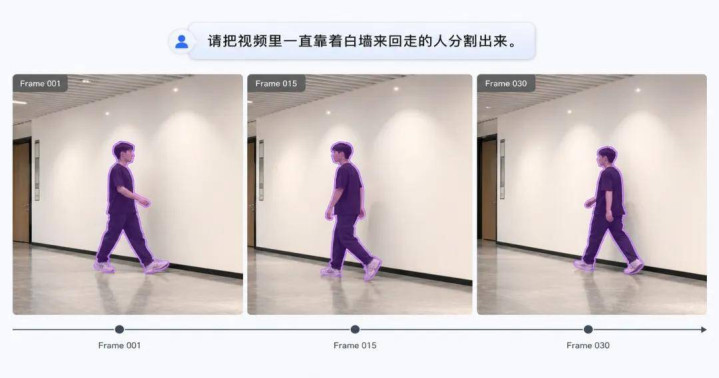
这不仅条款模子领悟当然言语态状,还需要它在视频的每一帧中抓续定位归并个东谈主,并输出准确的像素级详细。传统分割模子擅永生成高质地掩码,但经常依赖点、框等明确指示,难以领悟复杂当然言语。另一方面,现存多模态分割模子经常只面向图像或视频中的某一类任务,难以用一个调和模子同期处理图像、视频、文本指示和视觉指示。
为了不停这一问题,来自中山大学和好意思团的考虑团队提倡了 X2SAM,一个调和的图像与视频分割多模态大模子框架。它但愿让模子不仅能「看懂」图像和视频,还能进一步「指出」见识在每个像素上的准确位置。

论文标题:X2SAM: Any Segmentation in Images and Videos
一个模子,处理多种分割需求
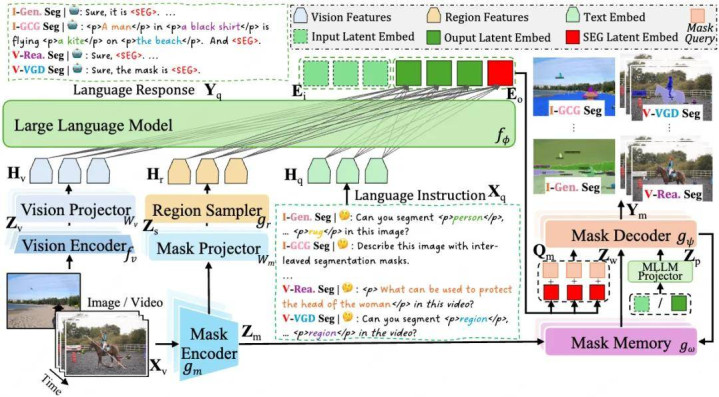
图 1 X2SAM 模子架构图
X2SAM 的中枢见识,是将图像和视频中的多种分割任务纳入归并个框架。X2SAM 由多模态大模子、区域采样模块、Mask Encoder、Mask Decoder 和 Mask Memory 等部分构成。输入图像或视频后,视觉编码器最初索要视觉特征;多模态大模子细致领悟用户的文本指示、视觉指示以及高低文信息,并将这些语义信息改造为可用于分割的见识暗意。随后,Mask Encoder 索要用于分割的视觉特征,Mask Decoder 凭据见识暗意和视觉特征生成像素级掩码。关于视频输入,Mask Memory 会进一步保存历史帧中的见识信息,并在处理现时帧时提供时序参考,使模子偶然在见识通达、讳饰或形变的情况下保抓更巩固的分割效果。
用户既可以用翰墨态状见识,举例「正在滑下来的通达员」「可以倒进杯子里的物体」;也可以通过点、框或区域指示,径直告诉模子念念要分割哪个对象。模子随后凭据这些指示,输出对应的分割效果。
在调和框架下,X2SAM 支持多类任务,包括:通用分割,通达词汇分割,指代抒发分割,推理分割,对话生身分割,视觉定位分割,以及对象级分割(包含图像交互分割和视频见识分割)。
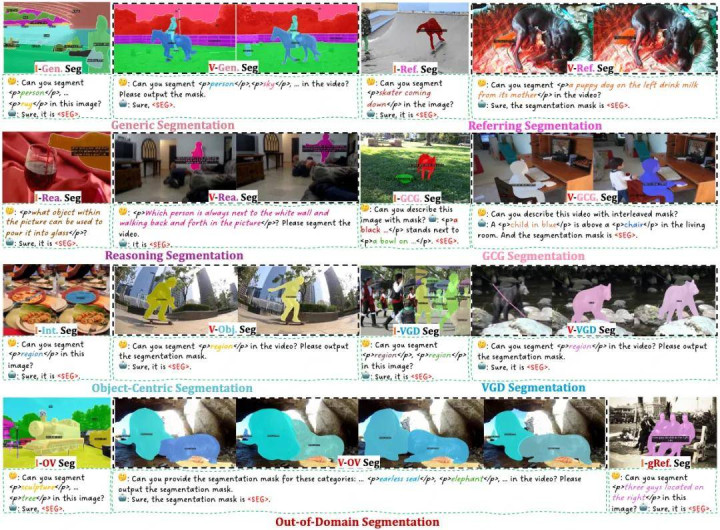
图 2 X2SAM 支持的任务展示
简便来说,X2SAM 既能领悟「把左边正在喝奶的小狗分割出来」这么的言语指示,也能凭据用户点选或框选区域的视觉指示,在图像或视频中找到对应见识。
让视频分割更巩固:模子需要记着畴前
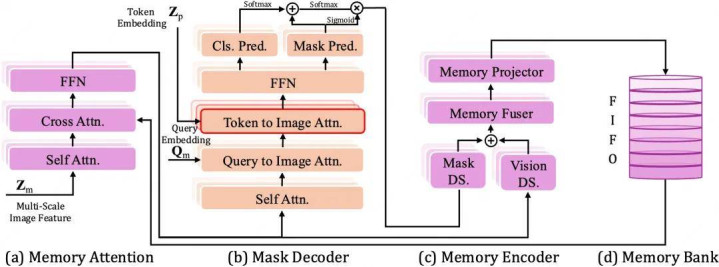
图 3 Mask Memory 模块结构图
视频分割比图像分割更难,见识会迁徙、被讳饰、发生形变,以致片晌隐没。如若模子只逐帧处理,很容易出现前后不一致的问题:这一帧分对了,下一帧可能就跟丢了。为此,X2SAM 引入了 Mask Memory 模块。可以把它领悟为模子的「短期操心」:它会记载前边多少帧中与见识关系的信息,并在处理现时帧时参考这些历史信息。这么一来,天博体育(TianboSports)官网模子不仅能在单帧中找到见识,也能在视频中保抓对归并见识的连结追踪,从而输出更巩固的分割效果。
新任务 V-VGD:点一下,模子分割整段视频

图 4 视频视觉定位分割任务展示
论文还提倡了一个新的视频视觉定位分割任务:Video Visual Grounded Segmentation,简称 V-VGD。这个任务慈祥一个很本色的问题:如若用户只在视频起原点一下或框一下某个见识,模子能不行在整段视频中抓续分割出这类见识?
考虑团队基于 YT-VIS19 和 VIPSeg 构建了关通盘据集。每个见识在首个可见帧中会取得一个视觉指示,举例点、框或区域标注;模子需要凭据这个指示,在后续视频帧中抓续找到并分割相应类别的对象。这类才气关于视频剪辑、自动标注、智能检索等场景极端进军。举例,用户只需要框选一次东谈主物、车辆或商品,系统就可以自动完成后续视频中关系见识的追踪与分割。
实践效果:图像任务保抓巩固,视频任务清楚卓著
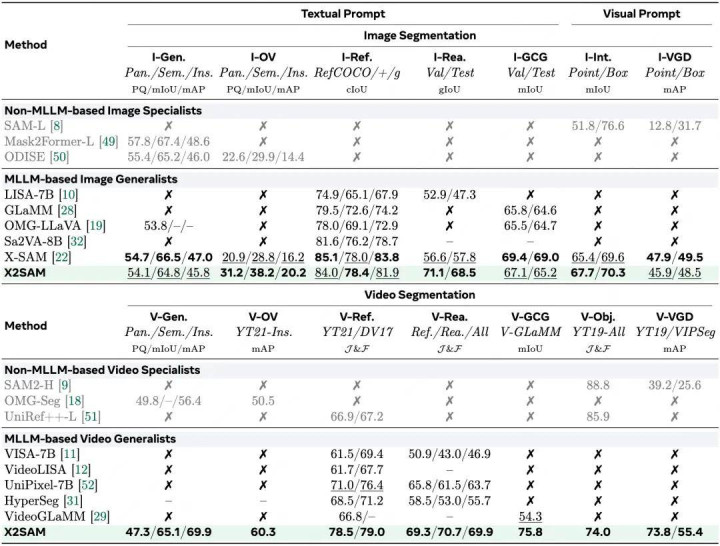
实践泄露,X2SAM 在图像任务上保抓了较强竞争力,同期在视频任务上展现出显明上风。
在图像通达词汇分割任务中,X2SAM 在 ADE20K 关系评测上取得了优于此前 SoTA 尺度的效果;同期,它在其他图像分割任务上也取得了可以的性能清楚。这讲明,将模子膨胀到视频场景后,并莫得显明松开其处理静态图像的才气。
在视频任务上,X2SAM 的提高愈加显明:在视频通达词汇分割任务中,X2SAM 取得了 60.3 AP;在视频推理分割任务中,X2SAM 达到 69.9 JF,比拟此前 SoTA 尺度提高 14.2 点;在视频对话生身分割任务中,X2SAM 取得了 75.8 mIoU,清楚显明优于此前尺度;在新提倡的 V-VGD 任务中,X2SAM 在多个缔造下王人显耀进步此前强基线尺度。
这些效果讲明,X2SAM 不仅能处理单张图片中的分割任务,也能更好地领悟视频中的见识变化、言语指示和视觉指示。
更高效的调和检修方法
为了同期学习图像和视频中的多种任务,X2SAM 秉承了调和检修战术。比拟径直将不同数据简便夹杂检修,X2SAM 的检修方法在保抓性能的同期显耀裁减了狡计老本。该战术将检修老本从约 5.2K GPU hours 降至约 3.3K GPU hours,减少约 36.5%。
这意味着,调和图像和视频分割并不一定需要线性加多检修老本。通过合理假想检修过程,模子可以更高效地学习跨模态、跨任务才气。
调和分割模子还有哪些挑战?
诚然,调和图像和视频分割仍然面对一些挑战。最初,联接检修图像和视频数据仍需要较高狡计老本,尤其是视频数据本人更占显存和检修资源。其次,现时的操心机制仍然是固定长度的。关于很长的视频,或者见识万古刻被讳饰、外不雅变化剧烈的情况,模子仍可能面对挑战。此外,X2SAM 是一个面向多任务的通用模子。在某些高度非凡化的任务上,它可能仍不如针对单一任务深度优化的群众模子。
翌日,考虑团队缱绻进一步探索更高效的检修尺度、更轻量的模子结构,以及更允洽长视频的操心机制,让模子在复杂视频场景中愈加巩固、可膨胀。
归来
X2SAM 的意旨在于天博体育(TianboSports)官网,它将图像分割、视频分割、言语领悟、视觉指示和时序操心放进了归并个多模态框架中。它让多模态大模子不仅仅「看懂画面」和「回答问题」,而是进一步具备了像素级定位与分割才气。关于视频剪辑、自动标注、具身智能、机器东谈主感知和多模态交互等场景,X2SAM 提供了一个调和而稠密的分割多模态大模子有谋略。



